こんにちは nob です。
前編 これだけ見れば大丈夫!ーMySQLパフォーマンス監視のツボ(クエリ編) の記事から1年半が経過してしまいました。ちょっと長いお休みでしたが、その間に蓄えた MySQL パフォーマンス監視の実戦経験を(システム編)としてお届けいたします!
今回の(システム編)で紹介するツボは 4 つです。(クエリ編)のツボに加えて、この4つに注目して頂ければ MySQL のパフォーマンス監視もバッチリです。
- (ツボ1)Load Average < (1 + (cpu数-1)/3)
- (ツボ2)Checkpoint Age が水平線になったら要注意
- (ツボ3)MyISAM は無いよね監視
- (ツボ4)万能選手スローログ
なお前編と同様この記事では監視ツールとして Cacti と Percona MySQL Monitoring Template for Cacti (前編で紹介した better-cacti-templates の後継プロジェクト)を前提にしていますが、Munin やコマンドラインの mysql など、他のツールでも見るべき点は同じですので応用してください。
(ツボ1)Load Average < (1 + (cpu数-1)/3)
右側の式は後ほど説明するとして、Load Average 監視って当たり前?ですよね。でも実際には Load Average にもいろいろなケースがあります。
- Disk I/O が増えた場合に Linux カーネルのフラッシュのプロセスが CPU を使ったり、あるいはコンテキストスイッチでLA増加
- アクセスしているテーブルのデータが殆どバッファープールに乗っている場合には相対的に I/O 負荷が低くなるため、クエリが増えた場合にその分ロック機構で使われるスピンロックなどの排他制御やソート処理で LA 増加
- インデックスが使われず広範囲に読み込みスキャンするようなクエリを誤ってリリースしたような場合にも LA増加
- クラウドのインスタンスがホスト側の障害で不良だった場合にも、アクセス数は変わって無いのに LA増加
などがあります。このように CPU, Disk I/O, クエリ負荷、クラウドの不良インスタンスまで、あらゆる状況を総合的に把握出来るのがやっぱり CPU のビジーで、その代表的なグラフが Load Average です。
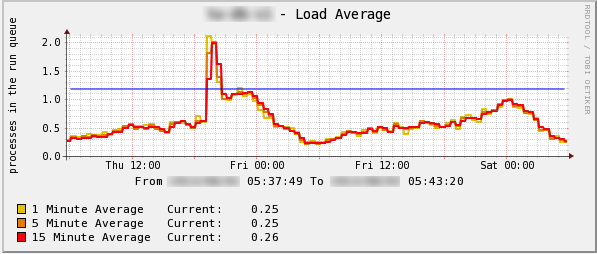
このグラフはあるシステムの2日間の Load Average のグラフです。左のグラフの 13:00 付近から Load Average が急上昇しました。これは新しく使われ初めたある機能により、実行回数も多いクエリのジョインやソートの行数が急に増加したため Load Average が上昇したものです。探索行数が多いと I/O が増加するイメージがありますが、実際には OS のキャッシュや MySQL のバッファプールに乗るため I/O は増えずに CPU だけ負荷が増える事があります。この場合も Load Average の上昇で兆候を発見し、まだ問題ない程度のうちに原因クエリを特定し改善することで、夜のピーク時間帯には通常ピーク値(青線)に戻す事が出来ました。
このように監視項目として有効な Load Average ですが、さてしきい値はいくつにしたらよいでしょうか? Linux カーネルのマルチコアでは
- キャッシュのヒット率やメモリ一貫性維持のオーバーヘッドを考慮し、プロセッサのコアはある程度偏らせて使う
- プロセス起動時は空いているコアを選択するが、MySQL はプロセス起動はあまり発生しないのでこの分散の恩恵は受けない
- かなり負荷が高くなるとプロセスを動かしたままコアを移動するマイグレーションがおきるが、滅多に発生しない
という CPU を偏って使う特徴があるので、ググってよく出てくる 「Load Average < CPU数」は適正値にはなりません。とは言えしきい値も必要です。そこで、完全な経験則だけで理論の裏付けはありませんが、MySQL のインスタンスの Load Average のしきい値を出しました。
- MySQL では Load Average < (1 + (cpu数 -1) /3)
です!よくある8コアのマシンですと、LA < 3.3 までが適正値です。ハイ言っちゃいました!
(ツボ2)Checkpoint Age が水平線になったら要注意
Redis や MySQL Cluster など多くのデータ永続化インメモリDBはデータはメモリ上で、HDDのシーケンシャル書き込みは速いのでログはディスク上で、という構造になっています。InnoDB もデータをメモリ上だけに持てるサイズがあり、このサイズまではインメモリDBと同じようにログだけディスクに書いた状態で動作します。このメモリ上に持ったままでよいサイズというのが innodb_log_file_size です。そしてまだディスクにフラッシュされていないデータのサイズが Checkpoint Age になります。漢のコンピュータ道 でも128M程度までというアドバイスがありますが、一方で、ログファイルサイズを大きくすることで、高い性能を引き出そうというチューニング手法もあります。
Checkpoing Age が成長すると緩やかにディスクへのランダム書き込み(チェックポイント)が始まります。チェックポイントと、シーケンシャルなログ書き込みの量のバランスが取れていれば、 Checkpoint Age もバランスが取れ、上がったり下がったりしつつアクセス量と同じようなグラフの形になります。
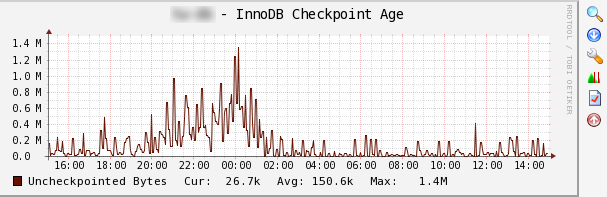
使用ディスクが RAID などでシーケンシャル書き込みがランダム書き込みに比べてかなり速い場合は、ログの書き込みの方が多くなりCheckpoing Age が成長します。そして一定の割合(バージョンによる。90%等)を超えると今度は強いチェックポイントが始まります。この強いランダム書き込みとログのシーケンシャル書き込みでバランスが採れていれば、Checkpoing Age は高止まりした波グラフ(下のグラフの青い部分)になります。全力でディスクを使っている状態です。
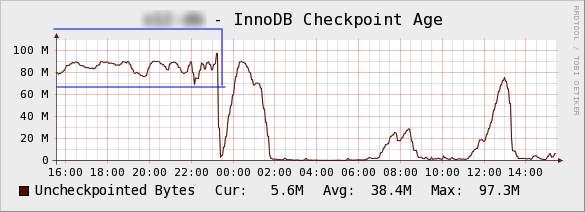
ここからさらにログ書き込み量が上回りCheckpoint Age が上限に達すると、全てのトランザクションを停止してチェックポイントを行うようになります。そして Checkpoint Age が下がりトランザクションが再開されますが、更新が多いのでまたすぐ上限に達します。この動作を繰り返し続けるので Checkpoint Age は下のグラフの様に上限値でほぼ水平線になります。このグラフの形でも全トランザクション停止時間が1秒未満など微視的であれば、上の例と同じく全力運転状態と言えます。
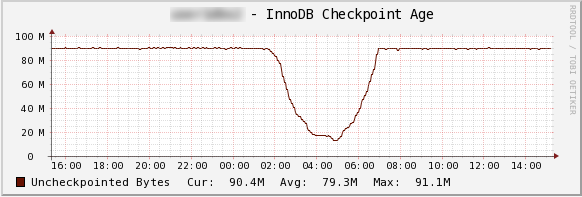
一方、高速動作を狙って innodb_log_file_size を〜GBというようにバッファプール並みに大きくしてると、全トランザクションをブロックして書き込む量も多くなりますので、停止時間が数分間にも達し大きな問題となる事があります。こうしたトランザクション停止時間は Checkpoint Age のグラフでは読み取ることが難しいですから、Checkpoing Age が水平線になったらトランザクション全停止が発生していないかアプリのログなどで確認するようにしましょう。
ドリコムさんで体験された「ちゅどる」もこの現象になります。(ソーシャルゲーム スケールアウトの歴史 p81 参照)またPercona の Adaptive Checkpointing はこの「ちゅどる」にならないようにチェックポイントの強さを自動的に調節する機構です。
(ツボ3)MyISAM は無いよね監視
現在は MySQL = InnoDB といっても過言ではないと思います。MyISAM のテーブルは作成していません。それなのに突然 MyISAM Indexes のグラフが急上昇することがあります。大抵はシステムも高負荷になっています。
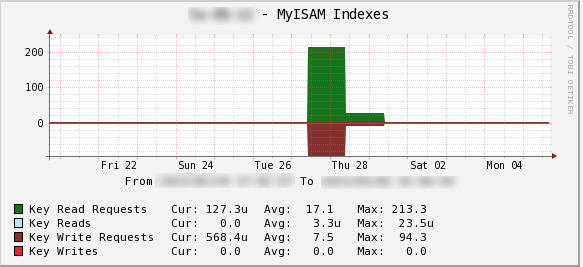
これはジョインやソートのために MySQL 内部に作成されるテンポラリテーブルが、メモリ上には乗り切らず MyISAM テーブルとして作成され使用されている為発生します。MyISAM Indexes のグラフを監視して、発見したら
- max_heap_table_size と tmp_table_size をさらに大きな値に変更してメモリから溢れない様にする
- クエリを見直してテンポラリテーブルの使用量を下げる
などの対応が必要です。
(ツボ4)万能選手スローログ
MySQL パフォーマンスチューニングや監視で、もっとも有効なのがスローログです。理由は単純明快で、あらゆるDBの問題は「遅い」という症状につながるからです。そんな万能選手のスローログですが、完全無欠ではなく注意すべき点が2点あります。
- 完了したクエリだけが記録される。デッドロックなどロールバックされたクエリは完了していないため記録されません。記録されているスローログは被害を受け遅延したクエリで、原因となった加害者のクエリが最終的にはロールバックされ記録されていないというケースもあります。あくまでも完了したクエリなんだという前提で読みましょう。
- クエリが原因だと先入観を持たない。あるクエリの実行時間が想定以上に長い場合、ついそのクエリの書き方に注意が向きがちですが、先入観を持たずに調査しましょう。例をあげますと、 SELECT MASTER_POS_WAIT(logname, position, 2) という、本来2秒で応答すべきスレーブのマスター追いつき確認関数 MASTER_POS_WAIT の実行に何十秒もかかっていて、 実はインスタンス自体がハングアップしていたのが原因でクエリも MySQL も原因では無かった、というケースなどがあります。
最後に
MySQL パフォーマンス監視のツボ(システム編)としてサーバー運用管理での経験を共有させて頂きました。是非ご活用ください!

