![]()
連載一覧
- 入門 Keras (1) Windows に Tensorflow と Keras をセットアップ
- 入門 Keras (2) パーセプトロンとロジスティック回帰
- 入門 Keras (3) 線形分離と多層パーセプトロン
- 入門 Keras (4) 多クラス分類 – Iris データを学習する
第4回はディープラーニングの応用では必須となる多クラス分類について Iris データの分類を通して学びます。
多クラス分類
第3回までのロジスティック回帰や多層パーセプトロンでは OR や XOR といった論理ゲートの学習について解説しました。論理ゲートの出力は 0 または 1 に分類することと同じであり、これを 2値分類 (binary classification) といいます。実際に分類や予測でディープラーニングを活用する場合は、たとえば手書きの数字の認識であれば 0 から 9 までの 10 種に分類するなどのように多数のなかから一つを選び出すというケースの方が多くなります。このように多種に分類することを 多クラス分類 (multiclass classification) また少数派ですが 多ラベル分類 ともいいます。ラベルはトレーニングに使われる正解データを意味していることもあります。
1対他戦略による2値分類への変換
多種に分類する問題は、複数の2値分類を組み合わせることで実現が可能です。下図のように X,Y 座標で 3 つの塊になっているデータを分類する場合、3つ線形分離を行って A, B, C のどれに出力があったかによって分類とすることが出来ます。
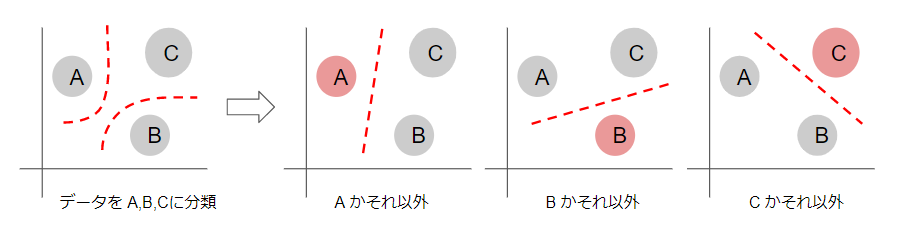
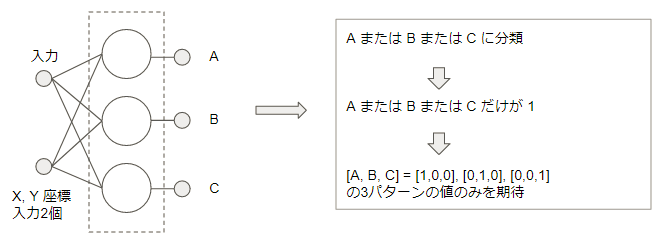
ここで使われてるように1対他の2値分類にて変換する戦略を One-vs-Rest(OvR), One-vs-All(OvA) または One-against-All(OAA) 戦略と言います。またトレーニング時の正解となるデータも元は多クラスで表現されていますので、[1,0,0] のようなバイナリ値の行列として変換することを One-Hot-Encoding などとも言われます。
Iris データセットを準備する
Python の著名な機械学習のライブラリに scikit-learn があります。 scikit-learn は GPU をサポートしていませんが、 (FAQ: GPU をサポートする予定はありますか?)学習用データの準備など周辺機能が充実していることもあり、機械学習のアルゴリズムの研究などのシーンで現在でも活発に利用されています。
今回は多クラス分類を体験するために scikit-learn に付属しているアヤメの分類データ Iris データセット を使います。
まずは jupyter-notebook を起動する前に、Anaconda Prompt で conda-forge リポジトリ(チャネルと言います)の scikit-learn をインストールします。
REM 第1回で作成した mykeras 環境を想定しています。あるいはみなさんが使っている環境を activate して実行してください activate mykeras conda install -c conda-forge scikit-learn
まず最初に Iris データセットをダウンロードします
from sklearn import datasets iris = datasets.load_iris()
Iris データセットは scikit-learn の Bunch オブジェクトになっています。Python の辞書(ディクショナリ)と同じように keys() が使えますので何が格納されているのか確認します。
In [2]: iris.keys()
Out [2]: dict_keys(['data', 'feature_names', 'target_names', 'target', 'DESCR'])
DESCR にデータの解説が入っています
以下のデータが data 部に格納されていて、
- sepal length がくの長さ
- sepal width がくの幅
- petal length 花弁の長さ
- petal width 花弁の幅
それぞれに対する正解データ(ターゲット、ラベル、などと言います)が target 部に格納されています。
- 0 Iris-Setosa セトナ、ひおうぎあやめ (檜扇菖蒲)
- 1 Iris-Versicolour バーシクル、ブルーフラッグ
- 2 Iris-Virginica バージニカ
取得した iris データセットから入力データ X と正解データとなる T を抜き出します。T の中味も見てみます。
In [3]: X = iris.data
T = iris.target
In [4]: T
Out [4]: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
ターゲットの値は 0, 1, 2 の3値でラベルが表現されています。これを [1,0,0] といった One-vs-Rest な配列に変換する必要があります。keras の np_utils にはこれを行ってくれる to_categorical という関数が用意されていますので使います。
In [5]: from keras.utils import np_utils
T = np_utils.to_categorical(T)
Using TensorFlow backend.
In [6]: T[:3] # 3つだけ表示
Out [6]: array([[ 1., 0., 0.],
[ 1., 0., 0.],
[ 1., 0., 0.]])
OR 回路や XOR 回路の場合は訓練データをそのまま再度テストにも用いていました。実際に応用するときは未知のデータに対して分類なり予測なり行うのが機械学習になりますので、もう少し本物っぽく事前に学習するデータと、テスト用のデータとを分けておきます。80% のデータを訓練用とし、残り20% を評価テストに使いましょう。
numpy の配列を自分でスライスして用意することも出来ますが、scikit-learn に train_test_split という便利な関数がありますので使います。train_ が訓練用、test_ がテスト、_x が入力データで _t が正解のターゲットです。
In [7]: from sklearn.model_selection import train_test_split
import numpy as np
np.random.seed(0) # 乱数初期化を固定値に
train_x, test_x, train_t, test_t = train_test_split(X, T, train_size=0.8, test_size=0.2)
len(train_x), len(test_x), len(train_t), len(test_t) # サイズ表示
Out [7]: (120, 30, 120, 30)
単純パーセプトロンでやってみる
データが揃いましたので、第2回と同じようにモデルを作成していきます。入力データは 4 種の特徴、次元 4 の配列で、3種に分類しますので出力するユニットを 3 とします。
ソフトマックス関数
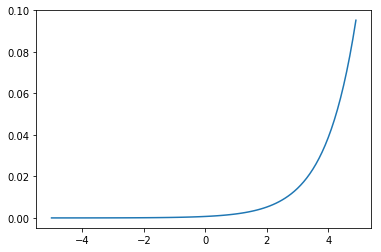
シグモイド関数は2値分類にはつかえますが、そのままでは多クラス分類には使うことが出来ません。多クラスに分類する場合の活性化関数には、入力が大きくなると出力が急激に上昇していくソフトマックス関数を用います。
最適化の方法も同じ SGD で、学習率も同じ 0.1、損失関数も同じ交差エントロピーですが多クラス用に使う categorical_crossentropy を使います。 epochs は最初控え目に 50 くらいから始め、狙っている正解率(95%など)に達するところまで徐々に増やしていくことにしましょう。
In [8]: from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import SGD
model = Sequential()
model.add(Dense(input_dim=4, units=3)) # 入力が4種の特徴、3つに分離
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.1))
model.fit(train_x, train_t, epochs=50, batch_size=10) # エポック50, ミニバッチ 10
Epoch 1/50
120/120 [==============================] - 0s - loss: 0.1860
Epoch 2/50
120/120 [==============================] - 0s - loss: 0.3083
**** 省略 ****
120/120 [==============================] - 0s - loss: 0.1532
Epoch 50/50
120/120 [==============================] - 0s - loss: 0.1285
Out [8]: <keras.callbacks.History at 0x1fcf2c7f7f0>
学習済みのモデルを使って、残しておいたテスト用データ test_x を分類し Y に格納してみましょう。2値分類と同じく predict_classes を使います。
In [9]: Y = model.predict_classes(test_x, batch_size=10) # ミニバッチは訓練時と同じく 10
10/30 [=========>....................] - ETA: 0s
In [10]: Y
Out [10]: array([0, 1, 1, 0, 2, 1, 2, 0, 0, 2, 1, 0, 2, 1, 1, 0, 1, 1, 0, 0, 1, 2, 1,
0, 2, 1, 0, 0, 1, 2], dtype=int64)
分類した結果の Y はクラス値(分類した値)で返っています。
テスト用の正解データ test_t は1対他比較のため OvR 行列化していますので、行列を要素が > 0 になっている列の番号(位置、インデックス)に変換して、結果データと正解データを比べてみましょう。
to_categorical で 0 と 1 だけの配列化したデータを、逆に分類の値に戻す方法はいろいろありますが numpy の where が条件を満たす行番号と列番号の配列を返してくれますので使います。行番号は使わないので _ 変数に代入して棄て、列番号だけ T_index に代入します。
In [11]: import numpy as np
_, T_index = np.where(test_t > 0)
print(T_index)
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0]
Numpy の配列は == で個々の要素まで比較してくれますので分類結果の Y と比較しチェックしましょう。
In [12]: Y == T_index
Out [12]: array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True, True, False, True, True, True, True, True,
True, True, True], dtype=bool)
1つだけ分類に失敗し Flase になったデータがありました。29/30 = 96% の正答率 となりました。
このように Keras で記述するととても短い量のコードですが、Iris データセットを学習して、適切に分類するという機能をニューラルネットを使って実現することが出来ます。
scikit-learn には Iris データセットのような Toy datasets が http://scikit-learn.org/stable/datasets/ に用意されています。この第4回までの Keras の練習にみなさんもぜひ取り組んでみてください!
最後に今日つかったコードをまとめておきます。
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import SGD
from keras.utils import np_utils
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
'''
データ準備
'''
np.random.seed(0) # 乱数を固定値で初期化し再現性を持たせる
iris = datasets.load_iris()
X = iris.data
T = iris.target
T = np_utils.to_categorical(T) # 数値を、位置に変換 [0,1,2] ==> [ [1,0,0],[0,1,0],[0,0,1] ]
train_x, test_x, train_t, test_t = train_test_split(X, T, train_size=0.8, test_size=0.2) # 訓練とテストで分割
'''
モデル作成
'''
model = Sequential()
model.add(Dense(input_dim=4, units=3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.1))
'''
トレーニング
'''
model.fit(train_x, train_t, epochs=50, batch_size=10)
'''
学習済みモデルでテストデータで分類する
'''
Y = model.predict_classes(test_x, batch_size=10)
'''
結果検証
'''
_, T_index = np.where(test_t > 0) # to_categorical の逆変換
print()
print('RESULT')
print(Y == T_index)
次回 1月23日予定の連載第5回は少し趣向を変えて、Keras で学習させたモデルを静的ファイルとして扱い、その学習済みモデルを使って Web (API) サービスを立てる簡単な方法について紹介します。

