
こんにちは。息抜きにくだらない話をします。
データ指向開発は、ゲーム業界で古くから時折話されているトピックのようです。素晴らしい資料として、Frostbyteさんのスライドへのリンク貼っておきます。 https://www.ea.com/frostbite/news/introduction-to-data-oriented-design
Frostbyteさんのスライドを見ると感じられるかもしれませんが、原理自体は簡単です。この件の大きな課題は、結局のところどのように現実的な開発として成立させるかだと思います。ただの配列としてすべてを用意したところで、人間が開発に耐えられなければ意味はありません。
データ指向の基本的な考え方
データ指向は、最終的には何らかの設計で利用しやすくラップするはずですが、初めに根幹の動作特性をよく理解して尊重する必要があります。冒頭でリンクしたFrostbyteさんのスライドが丁寧に説明をしていますが、今日ではSIMDを利用することが前提になるはずなので、その辺を加えつつこちらでも基本的な考え方を説明をします。
CPUは、あるデータ領域への初回アクセスなどでキャッシュミスが起きてしまった場合、続く領域を巻き込むような形で、キャッシュラインのサイズでの取得を行います。
(特にL1キャッシュラインのサイズは、C++17から
https://en.cppreference.com/w/cpp/thread/hardware_destructive_interference_size
として取得できます。)
その後に続けてメモリ的な隣接データへのアクセスを行う場合、キャッシュラインを活用できるため高速になることが想定されます。L1キャッシュそのものは通常キャッシュラインのサイズよりも大きいので、コードの一か所で複数の離れた領域にアクセスする場合、それら複数のL1キャッシュラインが保持できることが期待できます。つまり、ゲーム意図の数値らがDeinterleaveな形で物理配置されていれば、データ指向的に都合が良いのですね。
更にSIMDのレジスタに対しての操作も、値のLoad/Storeが隣接したメモリ領域に対しての行為になります。Deinterleaveされていれば、同時にSIMDも活用しやすいという事です。
(参考:_mm256_load_ps、_mm256_store_ps)
また、これらの話はマルチスレッドでの活用をさまたげません。偽共有に気を付けるくらいでしょうか。
データ指向開発の有利でない点
先述の基本的な考え方でDemystifyした形になりましたが、データ指向開発は魔法ではないのですね。ですから水平方向のやりとりには確実な利点はありません。一律で発生して内的に完結する処理については効果的なのですが、それ以外はやり方次第であり、よくて普通かそれ以下だということですね。
また、主観的な評価ですが、設計的にも難易度が高いと思います。
DDD等の思想に基づいたオブジェクト指向では、言語上の「クラス」「メソッド」「メンバ」といった論理的なコンセプトを利用して設計的世界観を自由に構築すると思います。一方でデータ指向開発では、データがどのように並んでいるかについてのハードウェア的制約が大前提として入ります。それさえも飲み込んで、うまくいなすのが設計の仕事ではありますが、少し上級だというきらいがあります。
とりあえずやってみた
データ指向開発の実現方法はケースバイケースだと思いますが、現実的に一例としてどう実現されるかを示せばそれなりに役に立つであろうと信じ、サンプルコードを適当に貼ってしまいます。
C++ですが、自分の基盤に依存しているため、抽象的に読んでください。
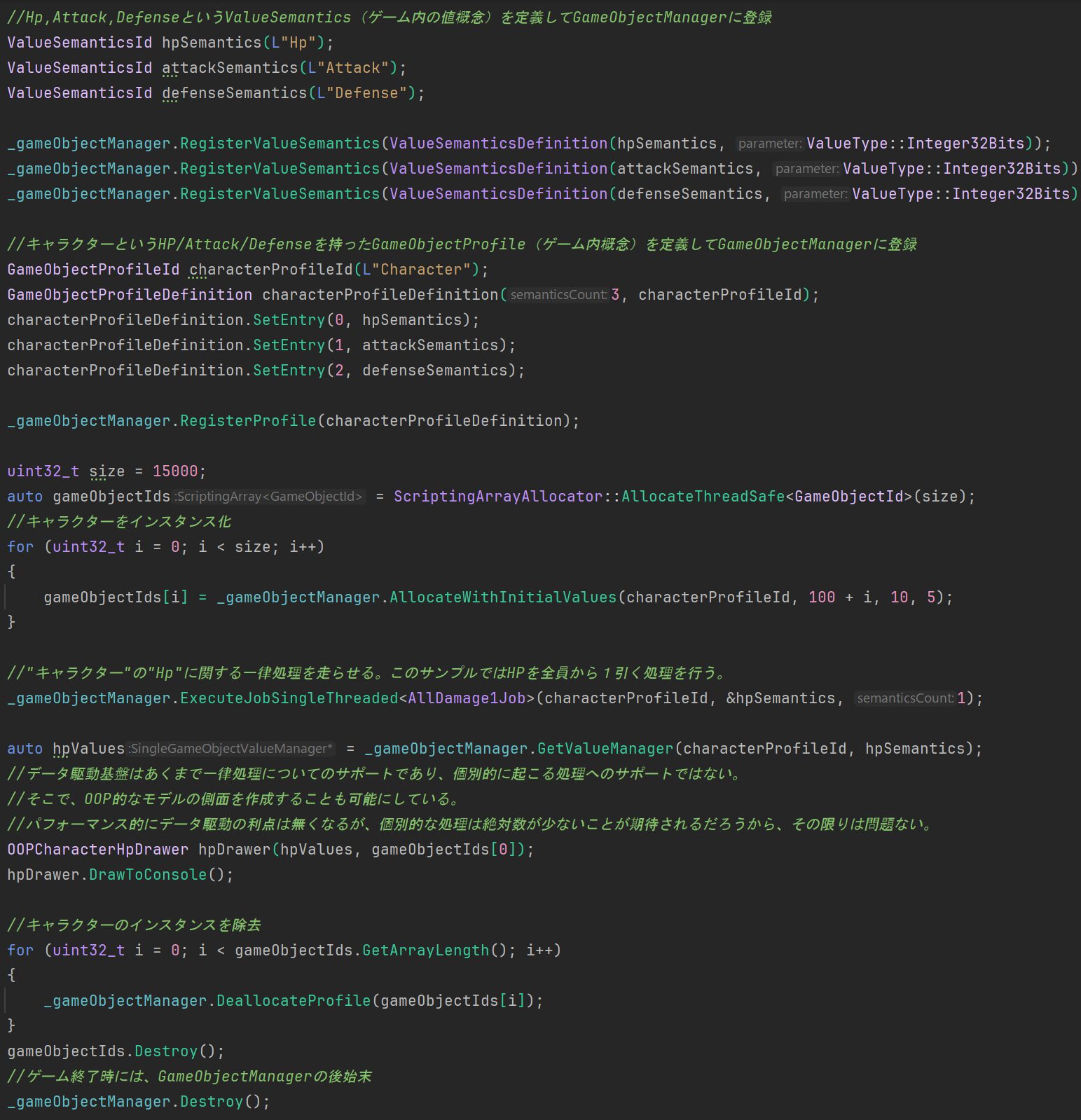
コメントを見ながら追って頂いた方が分かりやすいかもしれませんが、ザックリとした流れを説明します。
まず、ゲーム内的な意味としての値あるいはその意図(ValueSemantics)を定義し、それを組み合わせてゲーム内概念(GameObject)の形を定義します。この概念はProfileIdで指定できるものになります。
ProfileIdを利用して、実際にGameObjectのインスタンスを作成することができるようになります。一つのGameObjectのインスタンスは、ValueSemanticsで定義した値を一つ持ちますが、内部的な配置としてデータ指向になるように、配列として配置されています。しかし、外側からはその詳細は触れずに済むようになっています。

GameObjectでゲーム内のキャラクターや物体を表して、ゲームの実装を進めていくわけですね。
肝心のデータ指向的な一律処理(for的な処理)は、ここではExecuteJobSingleThreadedという処理で実行されています。任意の複数のProfileについての同じValueSemanticsを対象にした処理を実行したり、即時完了でなくマルチスレッドでのスケジュールにしたりもできます。

Jobの中身は、独自のSIMD基盤を利用して以下に示すような形で記述されております。内容は、全員のHPに1ダメージを与えるという意味不明なものです。

一応コメントしておきますが、計算が少なすぎて、SIMDによる計算はこの程度のケースではあまり直接的に高速化の役には立たないと思います。オブジェクト指向に対する高速化が見られるとすれば、データ指向によるキャッシュラインの活用率の改善によるものになるでしょう。
それはそれとしてSIMD基盤は自身の役割を適切に頑張るようになっておりまして、ランタイムでAVX512f/AVX2/SSE4.1基準から適切なものが選ばれるようにはなっています。(上の画像ではAVX2が選択されている)
SIMDの端数パディングもゼロコストで暗黙的に対応されます。(データ指向基盤のアロケーション管理側に工夫が入っているため)
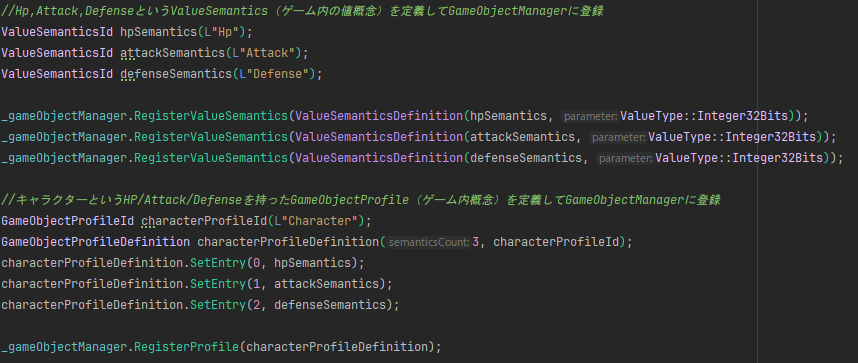
また、最後の方に「OOPCharacterHpDrawer」という輩がおりますが、オブジェクト指向と両立ができるという事です。ここでは控えていたGameObjectIdの配列の0番目にいるキャラクターについて、HPをコンソールに表示してます。
水平方向の関係や選択的な処理は、適宜OOPに切り替えた方が良いでしょう。

パフォーマンス
フェアな比較は難しいです。開き直って理想的な一律処理の差だけを雑な測定で示します。正当性は0として見てください。オブジェクト指向としての等価な処理として以下のようなものを定義します。
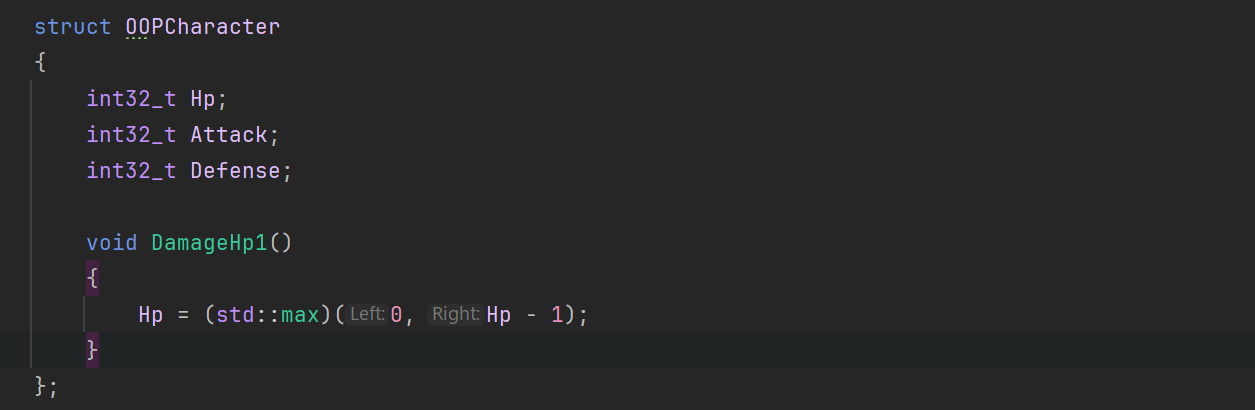

オブジェクトはC#でいう参照型的コンセプトで用意されるのが一般的でしょうから、ポインタを介した間接アクセスとしております。

こちらのデータ指向一律処理の区間と比較してみましょう。15000個のCharacterについて1ダメージ与える処理を行います。さて、結果は……


だいたいこんな感じになりました。(Release、最大最適化。std::chrono::system_clock::now()で計測。13900k@4.8Ghz, DDR5 4800 mt/s)
行っていることから差の理由はおおむね明らかだと思います。オブジェクト指向側が遅いのは、ポインタアクセスになっていることと、キャッシュラインが効率よく活用されない事が主でしょう。先ほども少し触れましたが、計算自体は少ないため、シングルスレッドとはいえこの場合ではSIMDが差を生んでいるかは、ぱっと見では分かりません。
ブログを書いている際に気づいたのですが、自前のアロケータの仕組み上、オブジェクト指向側も近い位置に全員連続して配置されているような気はします。より現実的な配置だと、もう少し差がつくかもしれません。
さいごに
データ指向は制約が強く、うまく成立させる設計はわずかしかない印象です。
そういえば、最近流行りのデータ指向設計に「ECS」という考え方があるようです。しかし、どのようなものであれデータ指向の利用は、個人的には(少なくともチーム開発では)あまりお勧めしません。原理から水平方向の関係は弱く、有利な状況が限定的であります。高速化の観点でも、例えばD3D12等の独自活用でGPU側を同時に最適化できていなければ、GPU boundになってしまいほとんど意味がない訳です。さらに記述自体も、自然だとは言えないと個人的には感じます。全体的にチームの練度が必要になりすぎるでしょう。
それでも、最速を目指すパターンの一つを理解しておくことは、開発者としては無駄になることは無いはずです。
★インフィニットループでは3Dゲーム開発にも取り組んでおります。興味がある方は是非採用情報をご確認ください。★

